Working with Documents
Excluded Documents
As content is processed within Discovery, certain documents are purposely skipped during the clustering process. In other words, these documents have been excluded from being added to the cluster. This is because the documents contain words, characters, or other elements that prevent it from logically being clustered with other documents. Therefore, all of these documents are combined into their own cluster and labeled as “Excluded”. However, the Excluded cluster can still be searched within the Wheel Interface, and is actually further broken down into smaller child-clusters. The following picture demonstrates this:
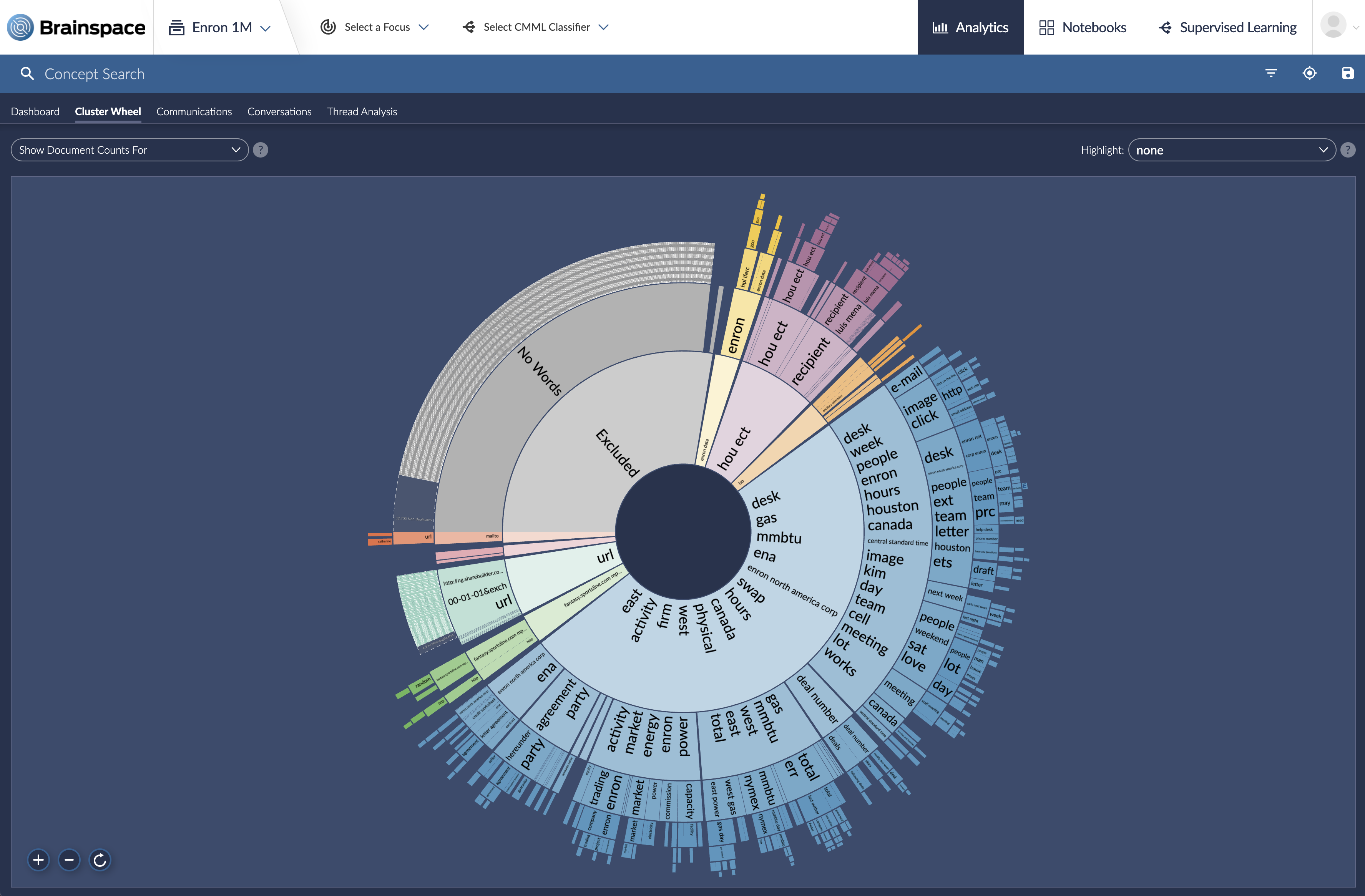
Child-clusters are titled according to their issue. The following section provides various exclusion types, as well as descriptions of why they occur:
Import Errors
During the initial import of documents during the build process, which is performed by your system administrator, it is possible that a document could not be ingested. This could be, among many possible reasons, because the document was not in a readable format or the size was deemed too large. Some of these can be corrected or adjusted by your system administrator.
Text Too Small
When documents are imported, to avoid the overhead of processing multiple documents that may simply say “scanned image”, the minimum document size and number of words are specified. Your system administrator can configure this minimum size.
No Shared Words
Consider a document whose vocabulary (text) does not match the rest of the document population and as a result is impossible to cluster. For example, if a user has a dataset like Enron that contains one email where the topic is completely different (let’s say Opera, and someone listed their five favorite operas and composers) the document would be unique, but it could not be clustered anywhere else within the population. It may also be in another language or be a spreadsheet with names, words or phrases.
No Words
It is possible that a document, such as a financial spreadsheet, may still be a text file yet have no words at all that could be extracted.
Vocabulary Too Small
Since a word has to show up in three documents before it’s considered part of the active vocabulary, it is possible that a document may have enough words but those words may not be in a sufficient number of other documents.
Duplicates and Near Duplicates
Brainspace recommends that document similarity should be used to expedite your review process but not be used in lieu of document review for Near Duplicates. The PD Document ID is assigned sequentially to documents that are similar and within a cluster. Note that there is no break in the numbering at the start of a new cluster. Review of documents in the PD Document ID order assures maximum efficiency of your search effort.
Similarity of documents is not just based upon matching text and character strings, but it is also based on the knowledge built into the brain as the data set is processed. The result is that documents that share concepts get associated with each other. Others factors to consider are some that would distort the clusters, such as the following:
Boilerplate—which is not used to determine document similarity otherwise forms filled out
Standardized templates
Email signatures
Refer to Duplicate Detection Update for info on algorithms used for duplicate detection in Brainspace Discovery 5.4.
The pivot document (centroid of the cluster) is selected based upon the mathematical similarity of a set of documents. The documents that fall within a given similarity to each other are used to build the cluster. Here are two simple illustrations:
Pivot Document
Consider 20 documents that all contain the US Constitution and the Bill of Rights (first ten amendments):
1 document has nothing else (just the Constitution and the Bill of Rights).
15 of the documents have some minor amount of commentary at the end of the document (Things like “what about the women?” or “cool there is no income tax!”).
1 document is the full constitution with the Bill of Rights and the additional 17 amendments.
1 document is the full constitution with the Bill of Rights and the Declaration of Independence.
1 document is the full constitution with the Bill of Rights, the Declaration of Independence and the additional 17 amendments.
1 document is the full constitution with the Bill of Rights, a bunch of Karl Marx quotes, the preamble from Fidel Castro’s last speech and a recipe for ceviche.
The one document with Constitution, the Bill of Rights and no comments would be the pivot.
The 15 with minor comments would have very high similarity scores.
The remaining documents would have the lowest similarity scores.
Note
The pivot document is not a document that has the most, or most relevant, information.
Document Similarity
Here is a non-scientific example of how documents can be assembled into a cluster and underscores the importance of reviewing your near dup documents.
Brainspace Discovery uses a Near Duplicate Document Threshold to calculate document similarity of .8 by default. This threshold is not a percentage match but rather a vector cosine (See http://en.wikipedia.org/wiki/Vector_space_model) used in document matching.
This threshold is used to determine how well documents match.
As the data set is processed, two documents that fall within that threshold form a cluster. For example,
A document with the Constitution and the Bill of Rights.
A document with the Constitution, the Bill of Rights and a comment “look no income tax”.
As further processing occurs, a document can come within the threshold of either or both of the documents in step 3 above and be added to the cluster. For example,
A document with Constitution, the Bill of Rights and a comment “look no women voting” more closely match the document with the Constitution, the Bill of Rights and the comment “look no income tax” than it matches the document with just the Constitution and the Bill of Rights.
More processing occurs and many documents with Constitution, the Bill of Rights and minor comments are encountered and added to the cluster.
The next document encountered does not have any comments.
It is just the Constitution and the Bill of Rights but it does not include Article II - however it is still within the threshold and added to the cluster.
There is then another document
It has the Constitution. It is missing Article II and III, and has the Bill of Rights. It is not within the threshold of the first set of documents with the comments identified in “4” but it is within the threshold of the document added in “6” above so it is added to the cluster.
There is then another document
It has the Constitution. However, it is missing Articles I, II and III and the Bill of Rights. It is not within the threshold of the earlier documents with the comments but it is within the threshold of the document added in “7” above so it is added to the cluster.
There is then another document
It has the Constitution. It is missing Article I, II and III, and the Bill of Rights and adds in an Article VIII giving us a king. It is not within the threshold of the earlier documents with the comments identified in “4” but it is within the threshold of the document added in “8” above so it is added to the cluster.
There is then another document
It has the Constitution, it is missing Article I, II. III, and IV and the Bill of Rights and adds in an Article VIII giving us a king. It is not within the threshold of the earlier documents with the comments but identified in “4” it is within the threshold of the document added in 9 above so it is ADDED to the cluster.
The cluster is then processed, pivot document calculated and similarity score against the pivot document calculated for each document in the cluster.
In the above, the pivot document would likely be the one with just the Constitution and Bill of Rights (due to the heavy weighting from documents processed in step 5) and the document from “10”. In this near dup cluster it would be given a very low similarity score. In the real world, what can affect the users view of document similarity is boilerplate. Boilerplate includes text and phrases that are ignored when processing for duplication and similarity but remain in place when viewed.
Potentially in step 5 above, if too many documents contained the preamble or Article V then it would be detected and treated as boilerplate and ignored.
Note that Near Duplicate clustering is directly correlated with the order in which documents are imported and analyzed. Since the Brainspace Discovery software is multi-threaded, Near Duplicate documents may be clustered slightly differently if the identical document population is analyzed a second time, or when near duplicates are part of a focus.
Boilerplate
What is Boilerplate? Boilerplate is a unit of text that appears over and over without change. These frequently appear in emails, as signatures, copyright statements, confidentiality statements and responsibility disclaimers. Boilerplate can affect the clustering and semantic brains in detrimental ways, so it’s best to eliminate it.
Boilerplate Example
This communication may contain information that is proprietary, privileged or confidential or otherwise legally exempt from disclosure. If you are not the named addressee, you are not authorized to read, print, retain, copy or disseminate this message or any part of it. If you have received this message in error, please notify the sender immediately by e-mail and delete all copies of the message.
The reason this raises concerns is that this boilerplate may show up in many of the documents and is semantically unrelated to the contents of the documents. However, its presence causes otherwise irrelevant words like addressee, error, delete and others to be the boilerplate, rather than the contents of the documents. Brains become distorted by the weight of these snippets of text. The user may see a cluster named confidential, with contents about lunch plans, simply because the email sender always included the boilerplate.
The system filters out all email headers and boilerplate for all document text that is analyzed for brains and clusters. For keyword queries we search the original text.
Since boilerplate is not considered when documents are clustered, documents that appear to be similar—such as forms and templates that are filled in get clustered together based upon their meaningful content.
Stemming and Tokenization
Tokenization is used to break up the stream of text into words, phrases, symbols, or other meaningful elements. The list of tokens becomes input for further processing and analysis. Brainspace uses proprietary tokenization mechanisms to enhance meaningful search results.
Characters like ‘ and - are not captured as part of tokens. Instead, they separate tokens. This is so that email addresses, URLs, hyphenated words, acronyms, etc., get stored as multiple tokens instead of single tokens.
Users can search for parts of email addresses, URLs, hyphenated words, acronyms, etc. and find them.
For example, no.body@devnull.com can be found by searching for no.body, no.body@devnull and no.body@devnull.com.
Searches for body or devnull.com also return some.body@devnull.com and any.body@devnull.com.
Documents such as abc.doc can be found by searching for abc.
Stemming is used to reduce inflected and derived words to their stem, base or root. The stem may not be identical to the morphological root of the word. It is usually sufficient that related words map to the same stem, even if this stem is not in itself a valid root.
For example, “jumping” get stemmed to “jump” so that documents with the word jumping appear in a search for jump, but “living” does not get stemmed to “live”.
Note that Brainspace uses proprietary tokenization mechanisms that mix rules and a lexicon. So while these examples are provided it is not easy to describe how the mechanism works simply from examples because of the additional built in vocabulary.
Example Work Flow
Consider this a best-case example. A document has been identified as being of interest. Copy the key area of text from that document that is relevant and use it as your search in the Concept Search interface to find additional documents with similar information:
Copy and paste the key document text into the Concept Search interface of Brainspace Discovery.
Hit the Expand Concept button.
Review the terms suggested by the brain.
Review documents from the results list on the right. (Hits in context are added to the search panel along the right so that you can easily identify why document appear in the list).
Click a document on the right and the text of the document appears in your window.
Once you have identified key documents, you can easily copy those doc IDs to another application using your clipboard or if configured to an external database.
Analyze the document population in more detail by exploring the Brainspace word/phrase list in the Concept Search results list.
Add emphasis to a key area of interest, the search will update and return to step 3.
This interactive process is key. By adding emphasis to key areas one by one, you start to understand more about your document population and identifying which elements drive your best results.
Use the document ID to identify its location on the wheel and easily identify any dupes, near-dupes and documents clustered near the targeted document.
Expand the search dialog.
Select pd_key.
Enter Doc ID into field.
The radial tree identifies where the document exists with the red compass pointer. Click the end of the compass pointer to drill down to the specific location of the document on the wheel.
Once you have zoomed into the cluster area of the document, select the 'x' to Clear Search. This clears your result list and allows you to explore the wheel location where the targeted document exists.
Gather desired results using the same process defined above.