Pre-filtering Data
Beginning with the release of Brainspace v6.1, Brainspace no longer excludes files larger than 16MB and is able to ingest most text-based documents with minimal issues.
Brainspace does not require pre-filtered data. Brainspace ingests all text and metadata. Although Brainspace can ingest all text and metadata, certain types of data--including complex data, non-text data, encrypted text, binaries, large number of duplicates, very large files, large volume of numbers, etc.--will require additional build-time and additional system resources.
Before attempting to ingest text and metadata that could cause excessive build-time and require additional system resources, Brainspace recommends removing data that will not add value to an investigation. In most cases, for example, images generally do not add value to an investigation, but they can add value if there is valid metadata associated with them. This will be searchable in the index but will not be analyzed for analytics by the brain. Likewise, use only “valuable” numbers or other non-text or minimal-text files when they contain useful metadata or titles that will add value to an investigation.
The suggestion for the general best practice is to filter out any document that exceeds an extracted text size of 1MB. If you can lower this threshold, the lower the better. The extreme upper limit of our suggested extracted text size is 16MB, but this should be a limit that is worked up to and not a starting point.
In most cases, the overly large files are Excel or other database type records, or even the extracted text of a binary file. Before ingestion, filter out these documents, as well as the Unrecognized, No Data, Multimedia documents, etc. (These files will offer little to no value to your dataset.)
A good benchmark to start with is filtering out any document over 1MB in Extracted Text Size. (The optimal benchmark is 16KB, but this can be adjusted depending on the need.) Brainspace can handle the larger files in most cases, but be aware of what they are before sending.
We can handle anything up to 1GB of text (java limitation) but we would never advise you to send documents that large.
Ultimately, the extracted text size limit will depend upon your infrastructure, specifically the amount of RAM and disk space on your server, but the above outlines our suggested general best practice.
Resolving Incremental Build Failures
If you encounter an incremental build failure, check the vocabulary.txt file for lines that look like the following image:
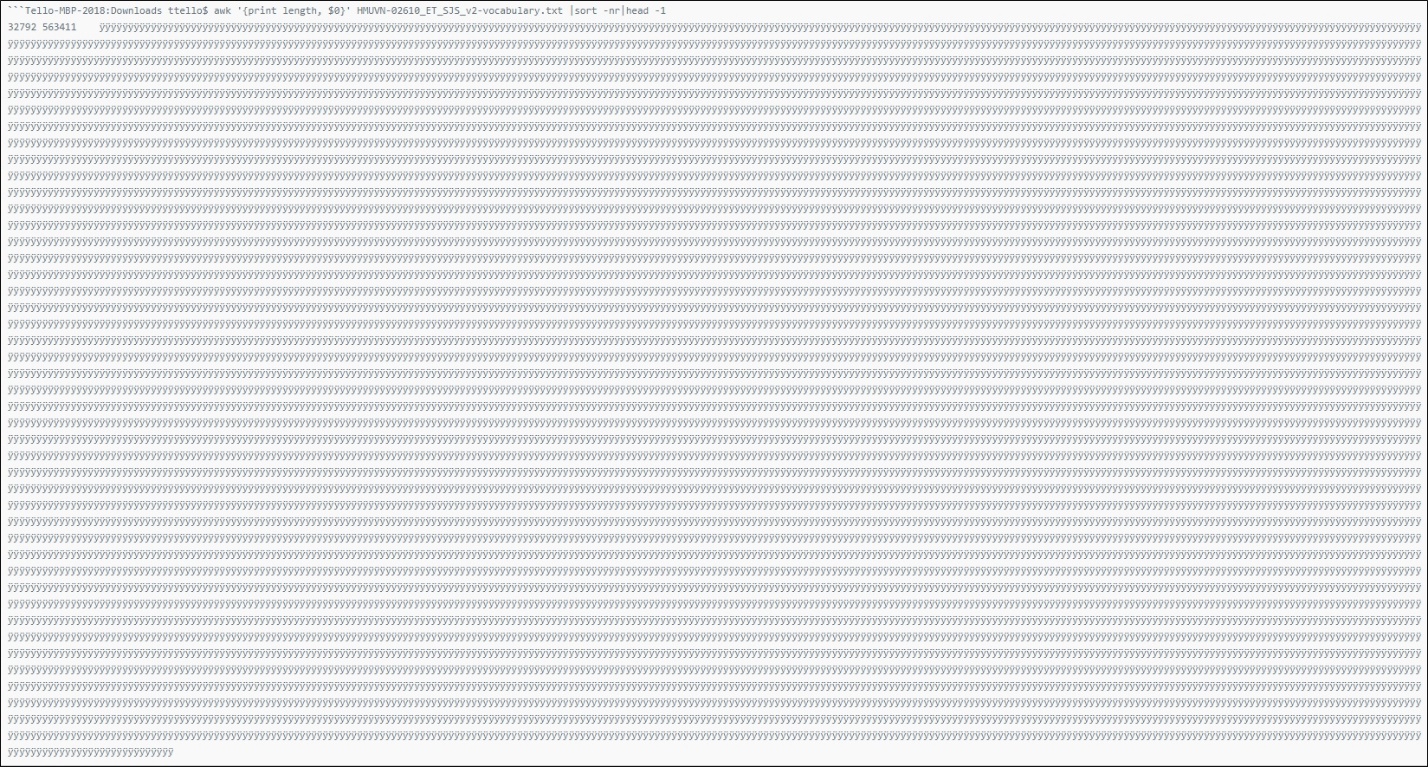 |
Brainspace first encodes the line, and then loads it into a 64KiB buffer, which is what causes the build failure when data is contains encrypted text, binaries, etc.
To recover from an incremental build failure caused by incompatible data, rebuild the dataset or locate and remove the documents that are causing the incremental build failure.